扫码关注
扫码关注























01
引言
人工智能基础设施的快速扩张对数据中心连接性提出了更高要求。当人工智能集群扩展至容纳 100,000 个或更多 GPU 和 XPU,达到 gigawatt 级功耗时,网络骨干必须同步演进以支撑这种转变。这个演进的基石在于 102.4T 以太网交换机搭配低功耗 1.6T 光收发器,两者共同提供现代人工智能工作负载所需的高带宽、低延迟和功率效率。
02
基础技术:200G/Lane SerDes
当前人工智能基础设施扩展的核心在于 200G/lane SerDes 技术,已成为高速互连的基础构建模块。这项技术嵌入整个连接堆栈中,从 102.4T 交换机到 1.6T 光收发器和重定时器,同时支持单一服务器内的 scale-up 架构以及连接大量运算资源集群的 scale-out 网络。Broadcom 作为业界先驱,首家提供涵盖交换芯片、光学数字信号处理器、重定时器和光学元件的完整端到端 200G/lane 连接解决方案。相较于前一代 100G/lane 技术,200G/lane 技术将每通道容量提升一倍,不仅增加带宽密度,还通过减少特定总吞吐量需求的元件数量,降低整体系统功耗和成本。
03
技术突破:400G/Lane DSP 与光学元件
延续 2025 年 OFC 展会发表的 400G 电吸收调制激光和光电二极管的发展动能,Broadcom 在 2026 年 OFC 展会推出业界首款 400G/lane 光学数字信号处理器。Taurus BCM83640 标志着一个重要里程碑,专门针对 1.6T 收发器应用优化,并构成 Taurus DSP 平台的基础,该平台将支持下一代 3.2T 光收发器模组。这款创新元件作为 8:4 齿轮箱 PHY 运作,具备 400G/lane 串行光学接口,完全符合现行 IEEE 标准,同时与 Broadcom 的 400G EML 和光电二极管元件无缝互通。400G/lane 光学 DSP 与 400G EML/PD 技术的整合,使光学模组制造商能够开发符合现代人工智能数据中心严格要求的低成本、低功耗 1.6T 收发器。
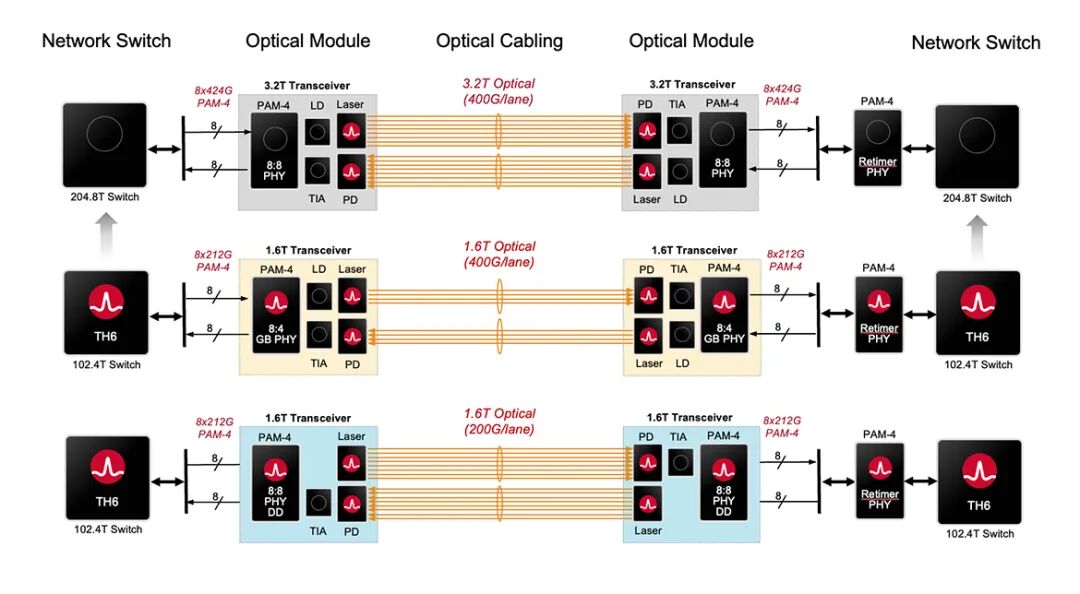
图 1:不同世代(204.8T、102.4T 配置)的网络交换机和光学模组架构演进,包含 3.2T、1.6T 光收发器及对应的光学线缆实现方式。
04
未来发展:迈向 204.8T 及更高规格
过渡至 400G/lane 技术不仅是渐进式改进,更是人工智能连接基础设施的下一个演进阶段。通过在不按比例增加功耗、成本或物理占位的情况下将每通道吞吐量提升一倍,400G/lane 信号传输在网络带宽、延迟和整体效率方面带来显著改善。下一代系统将采用 204.8T 交换机搭配 3.2T 光收发器,两者都采用专为人工智能基础设施需求设计的 400G/lane 电气接口。这种架构对齐创建了电气与光学输入 / 输出速度之间的一对一对应关系,大幅简化 3.2T 光学模组设计,同时提升可靠性并降低制造复杂度。通过在当今人工智能数据中心中启用 400G/lane 光学链路,Broadcom 建立了通往具备原生 400G/lane 电气接口的 3.2T 光收发器的明确迁移路径,确保与下一代 204.8T 交换平台的无缝相容性,并为人工智能基础设施投资提供未来保障。