扫码关注
扫码关注























龙芯3A5000是龙芯中科研发的首款支持龙芯自主指令集(LoongArch)的通用多核处理器,主要面向桌面计算机和服务器应用。龙芯3A5000片内集成4个64位LA464高性能处理器核、16MB的分体共享三级Cache、2个DDR4内存控制器(支持DDR4-3200)、2个16位HT(HyperTransport)控制器、2个I2C、1个UART、1个SPI、16路GPIO接口等。龙芯3A5000中多个LA464核及共享三级Cache模块,通过AXI互连网络形成一个分布式共享片上末级Cache的多核结构。
采用基于目录的Cache一致性协议来维护Cache一致性。另外,龙芯3A5000还支持多片扩展,将多个芯片的HT总线直接互连就形成更大规模的共享存储系统(最多可支持16片互连)。
LA464是支持Loongarch指令集的四发射64位高性能处理器核,具有256位向量部件。LA464的结构如图所示,主要特点如下:
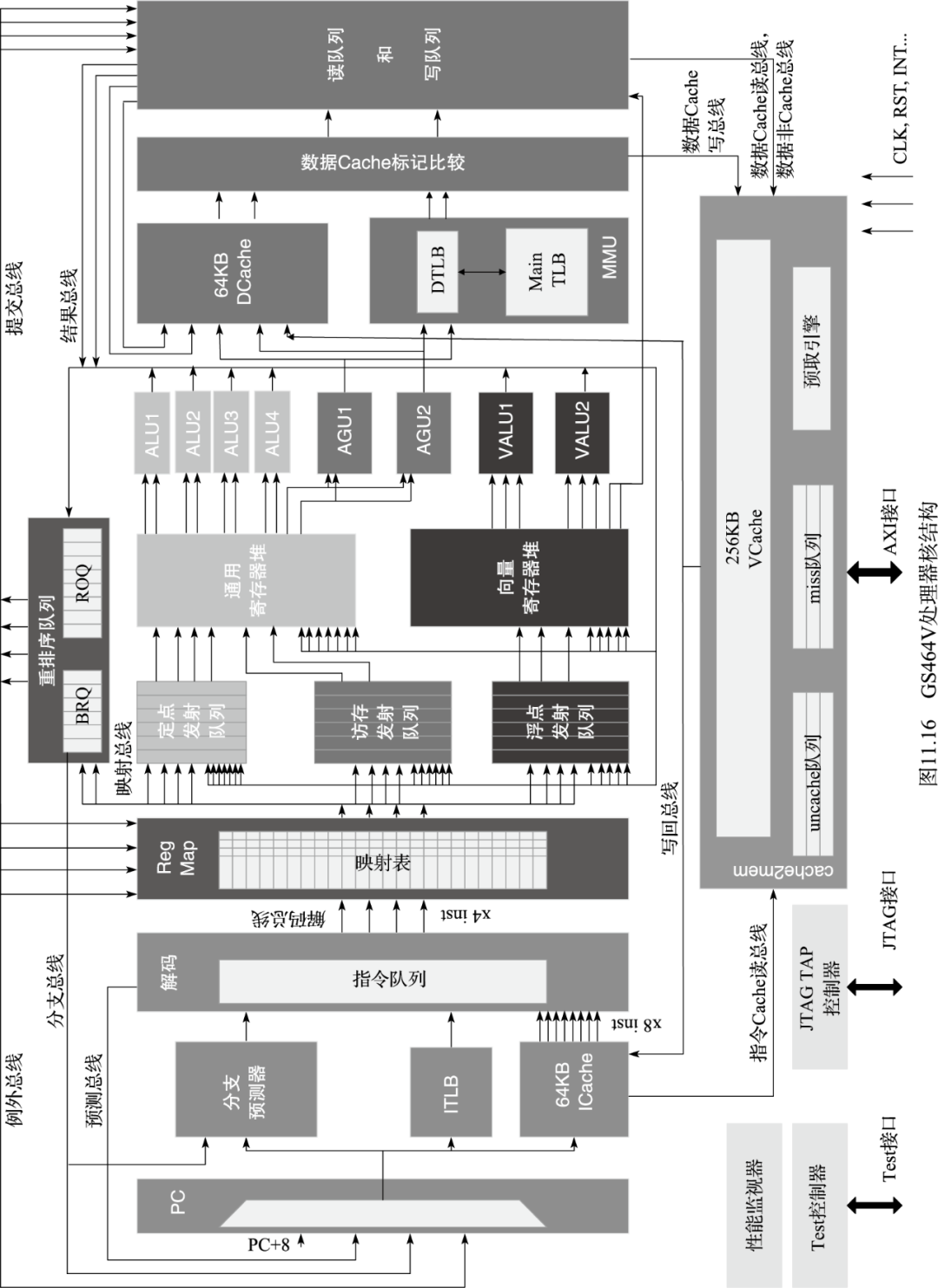
四发射超标量结构,具有四个定点、两个向量、两个访存部件;支持寄存器重命名、动态调度、转移预测等乱序执行技术;每个向量部件宽度为256位,可支持8个双32位浮点乘加运算或4个64位浮点运算;一级指令Cache和数据Cache大小各为64KB,4路组相联;牺牲者Cache(Victim Cache)作为私有二级Cache,大小为256KB,16路组相连;支持非阻塞(Non-blocking)访问及装入猜测(Load Speculation)等访存优化技术;支持标准的JTAG调试接口,方便软硬件调试。
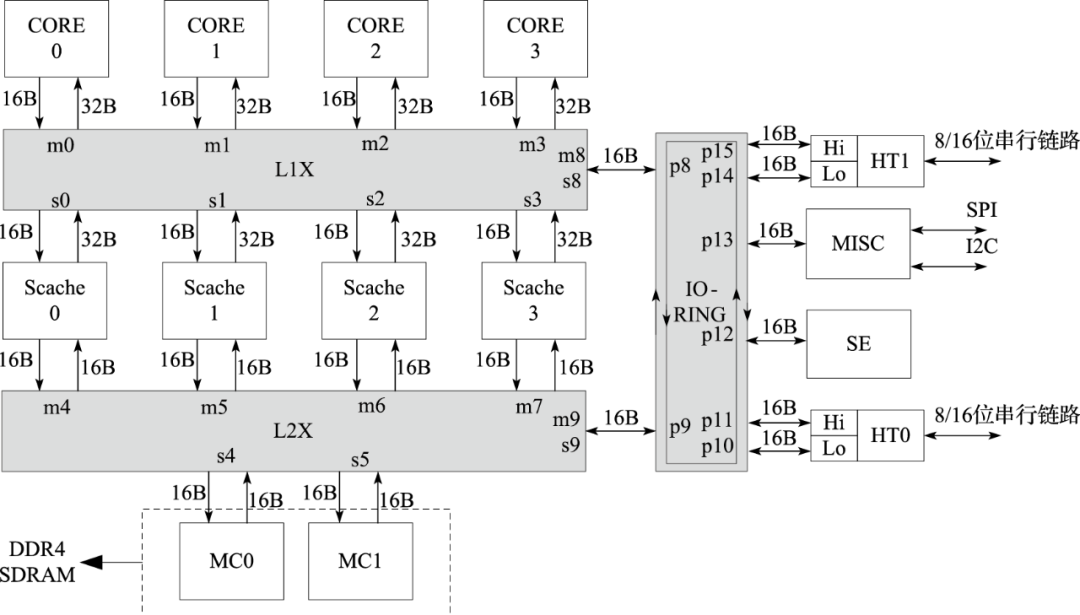
龙芯3A5000芯片整体架构基于多级互连实现,结构如上图所示(图为芯片版图)。

第一级互连采用5x5的交叉开关,用于连接四个LA464核(作为主设备)、四个共享Cache模块(作为从设备)、以及一个IO端口连接IO-RING。IO端口使用一个Master和一个Slave。第二级互连采用5x3的交叉开关,连接4个共享Cache模块(作为主设备),两个DDR3/4内存控制器、以及一个IO端口连接IO-RING。IO-RING连接包括4个HT控制器,MISC模块,SE模块与两级交叉开关。两个HT控制器(lo/hi)共用16位HT总线,作为两个8位的HT总线使用,也可以由lo独占16位HT总线。HT控制器内集成一个DMA控制器,DMA控制器负责IO的DMA控制并负责片间一致性的维护。上述互连结构都采用读写分离的数据通道,数据通道宽度为128bit,与处理器核同频,用以提供高速的片上数据传输。此外,一级交叉开关连接4个处理器核与Scache的读数据通道为256位,以提高片内处理器核访问Scache的读带宽。
龙芯3A5000主频可达2.5GHz,峰值浮点运算能力达到160GFLOPS。
龙芯3A3000 7A1000桥片中CPU、GPU、DC间的同步与通信为例说明处理器与IO间的通信。如图所示,龙芯3A3000处理器和龙芯7A1000桥片通过HyperTransport总线相连,7A1000桥片中集成GPU、DC(显示控制器)以及专供GPU和DC使用的显存控制器。CPU可以通过PIO方式读写GPU中的控制寄存器、DC中的控制寄存器以及显存;GPU和DC可以通过DMA方式读写内存,GPU和DC还可以读写显存。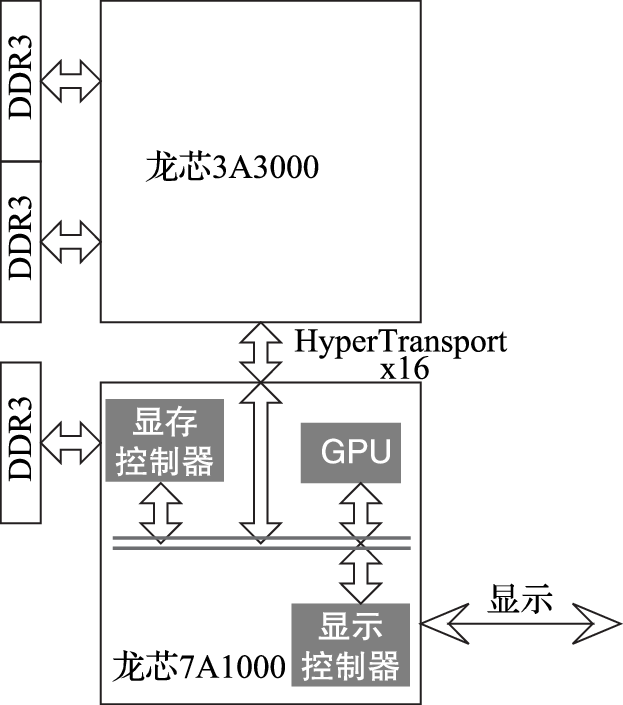
CPU或GPU周期性地把要显示的数据写入帧缓存(Frame Buffer),DC根据帧缓存的内容进行显示。帧缓存可以分配在内存中,GPU和DC通过DMA方式访问内存中的帧缓存;在独立显存的情况下,帧缓存分配在独立显存中,CPU直接把要显示的数据写入帧缓存,或者GPU通过DMA方式从内存中读取数据并把计算结果写入帧缓存,DC直接读取帧缓存的内容进行显示。根据是否由GPU完成图形计算以及帧缓存是否分配在内存中,常见的显示模式有以下四种。
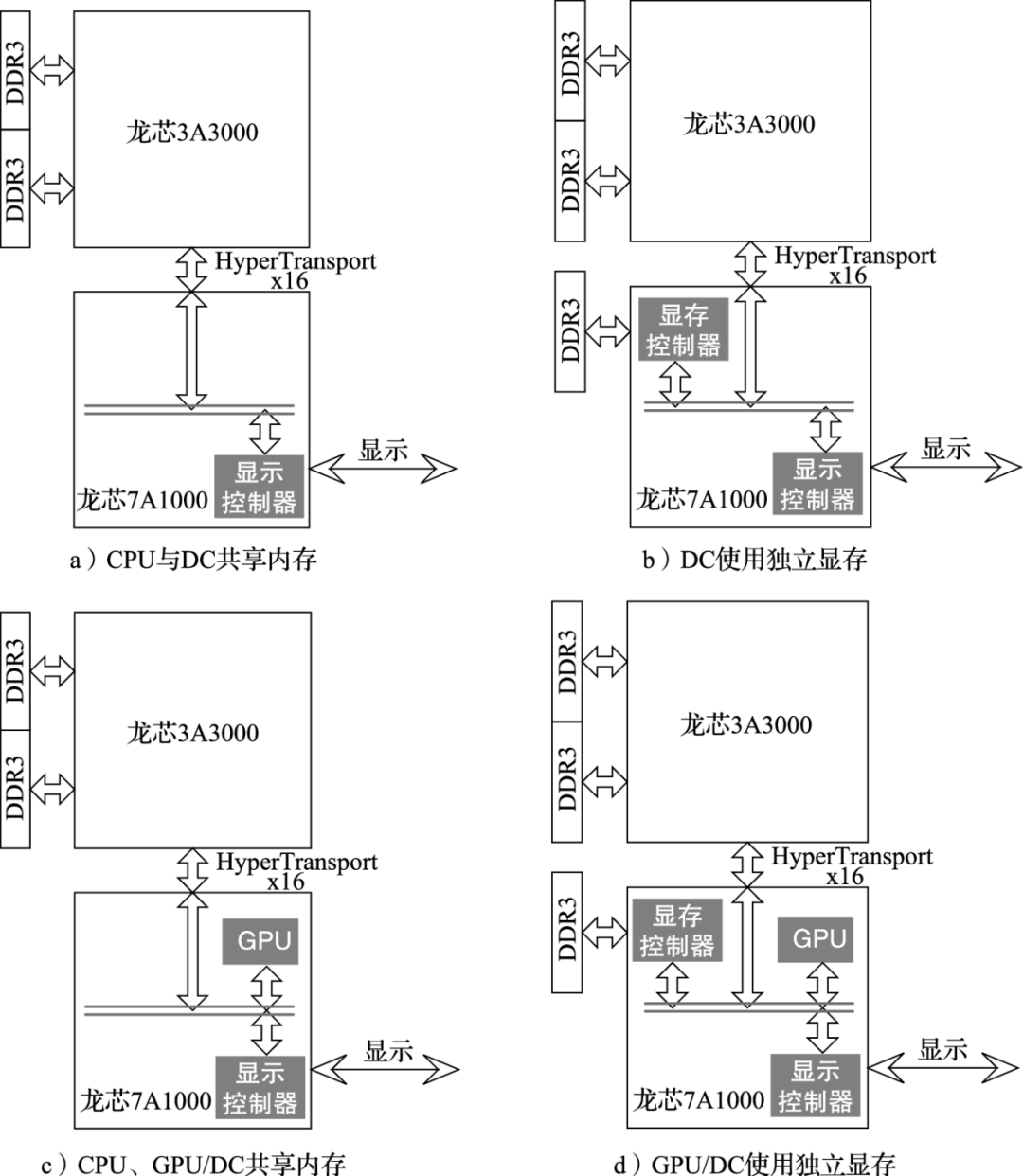
模式一:不使用GPU,CPU与DC共享内存。不使用桥片上的显存,而在内存中分配一个区域专供显示使用,这个区域称之为帧缓存(framebuffer)。需要显示时,CPU通过正常内存访问将需要显示的内容写入内存中的帧缓存,然后通过PIO方式读写DC中的控制寄存器启动DMA,DC通过DMA操作读内存中的帧缓存并进行显示,如图a所示。
模式二:不使用GPU,DC使用独立显存。DC使用桥片上的显存,这个区域称之为帧缓存。需要显示时,CPU将需要显示的内容从内存读出,再通过PIO方式写入独立显存上的帧缓存,然后通过PIO操作读写DC中的控制寄存器启动DMA,DC读显存上的帧缓存并进行显示,如图b所示。
模式三:CPU与GPU/DC共享内存。需要显示时,CPU在内存中分配GPU使用的空间,并将相关数据填入,然后CPU通过PIO读写GPU中的控制寄存器启动DMA操作,GPU通过DMA读内存并将计算结果通过DMA写入内存中的帧缓存,CPU通过PIO方式读写DC中的控制寄存器启动DMA,DC通过DMA方式读内存中的帧缓存并完成显示,如图c所示。
模式四:GPU/DC使用独立显存。需要显示时,CPU在内存中分配GPU使用的空间,并将相关数据填入,然后CPU通过PIO读写GPU中的控制寄存器启动DMA操作,GPU通过DMA读内存并将计算结果写入显存中的帧缓存,DC读显存中的帧缓存并完成显示,如图d所示。