No data
写文章
发视频
提问题
传文档
电子设计讲堂 专家精讲课程 知识传授指导
前沿电子资讯 电子技术干货 经验知识总结
设计问答汇总 在线答疑解惑 达人倾囊相授
专业行业文档 知识类目清晰 要点一键下载
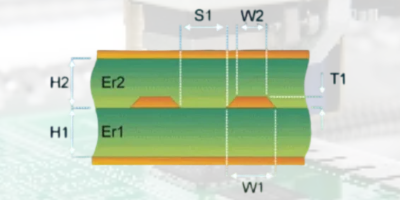
阻抗计算神器 多层板阻抗 凡亿层压结构
PCB设计指南 EDA设计指南 封装设计指南
Symbol下载 PCB封装下载 3D模型下载
凡亿Skill工具 敷铜脚本插件 快速添加差分
技术题库汇总 如何谈薪资 常见面试技巧
优质电子公司 专业人才简历 高薪一键触达
凡亿是国内领先的电子研发和技术培训提供商,是国家认定的高新技术企业。以“凡亿电路”“凡亿教育”作为双品牌战略,目前近110万电子会员,技术储备为社会持续输送7万余人高级工程师,服务了1万多中小型企业合作伙伴。
简介YT8521S 是一款高度集成的以太网收发器,符合 10BASE Te、100BASE-TX 和 1000BASE-T IEEE 802.3 标准。它提供了经由 CAT5E UTP 电缆传输和接收以太网数据包所需的所有物理层功能。YT8
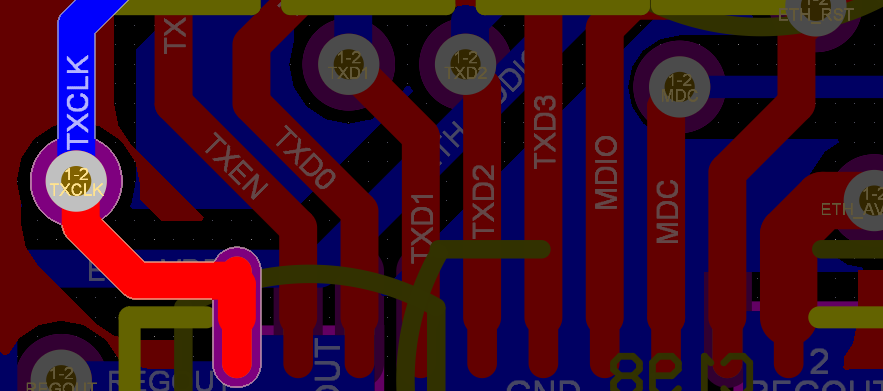
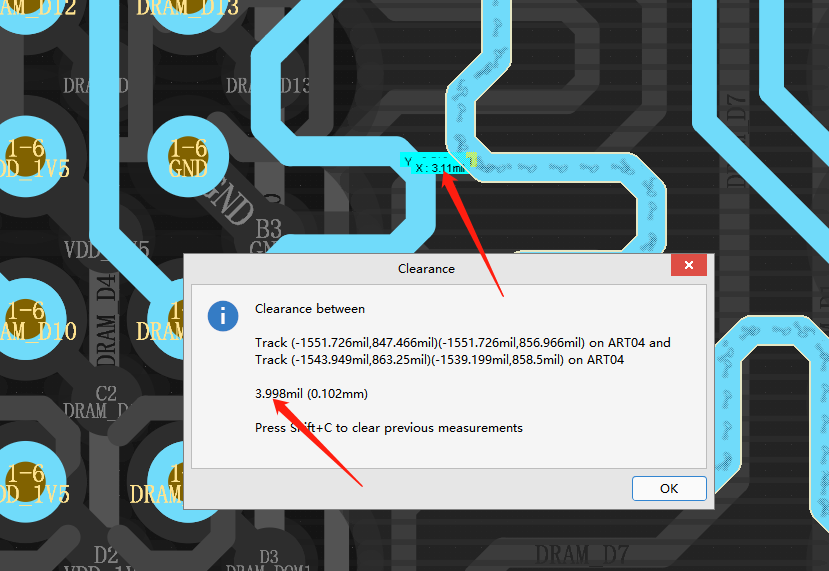
焊盘出线不规范,不能从侧面出线,出线的时候线宽不要大于焊盘宽度这个变压器下面的挖空可以在宽一点rx和tx没有做等长,信号线中间不要变化线宽时钟没有包地处理两个不同的地除跨接器件外其他的地方连接要不小于1.5mm差分对内等长误差大于5mil以
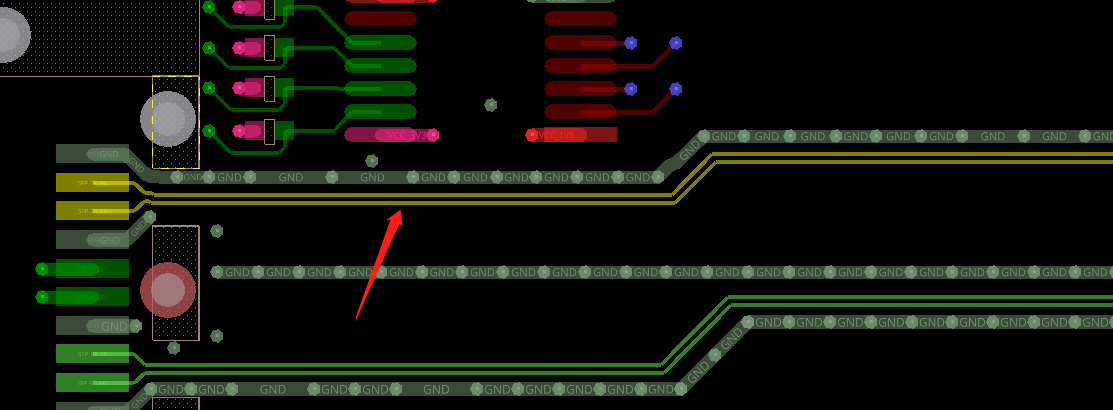
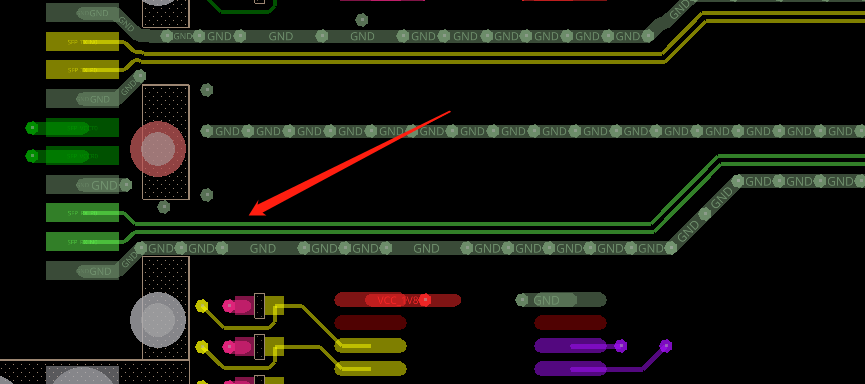
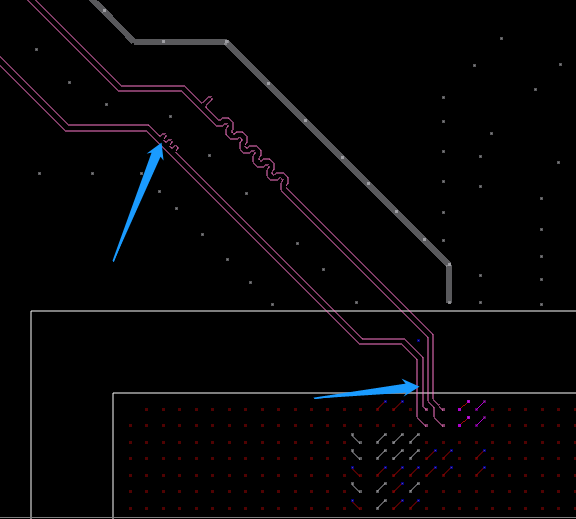
差分信号尽量包地包完全:此处上述一致原因,可以优化:此处电源信号的铜皮尽量优化宽一点,不然整体的铜皮载流量是从最窄处计算的:差分对内需要做等长处理,误差胃5MIL:此对差分没有做等长处理:其他的没什么问题。以上评审报告来源于凡亿教育90天高
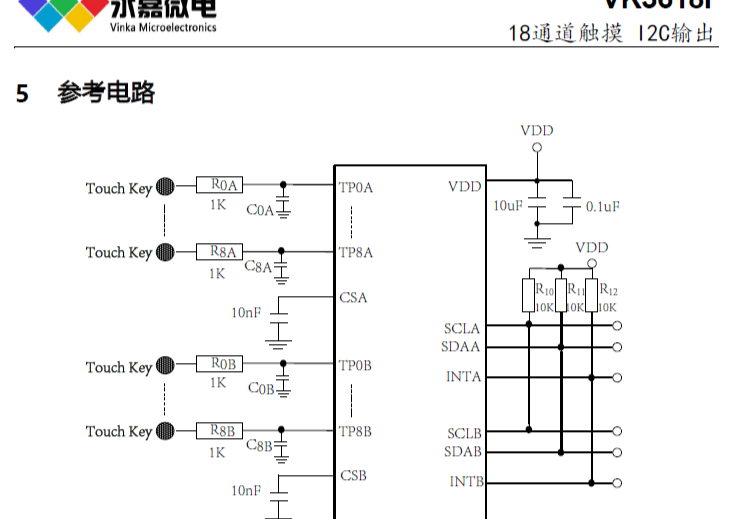
产品品牌:永嘉微电/VINKA 产品型号:VK3618I封装形式:SSOP28 概述VK3618I具有18个触摸按键,可用来检测外部触摸按键上人手的触摸动作。该芯片具有较 高的集成度,仅需极少的外部组件便可实现触摸按键的检测。 提供了2组I
很多新手工程师在PCB设计时,经常被要求将Perberl转换成Gerber文件,但由于这方面接触不深,导致转换过程中没有顺利进行,最终文件转换失败,根本原因还是在于没有好好遵循以下原则!1、D码匹配精度控制D码匹配是转换过程中的关键步骤,其
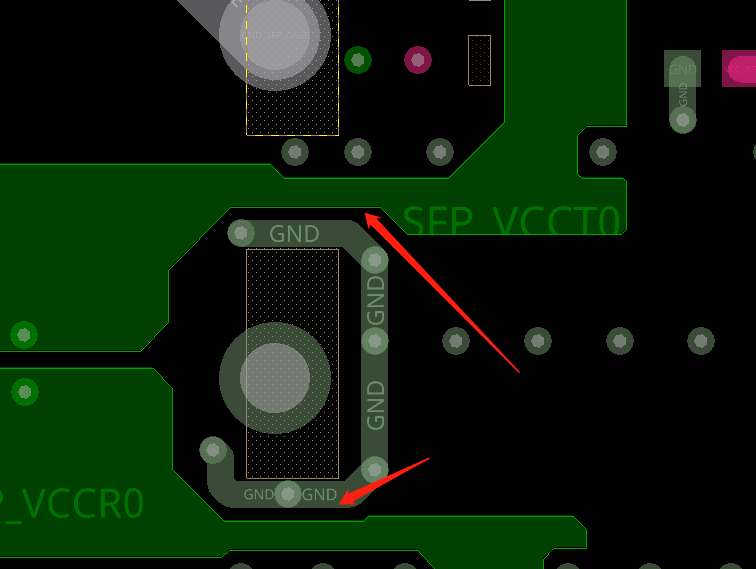
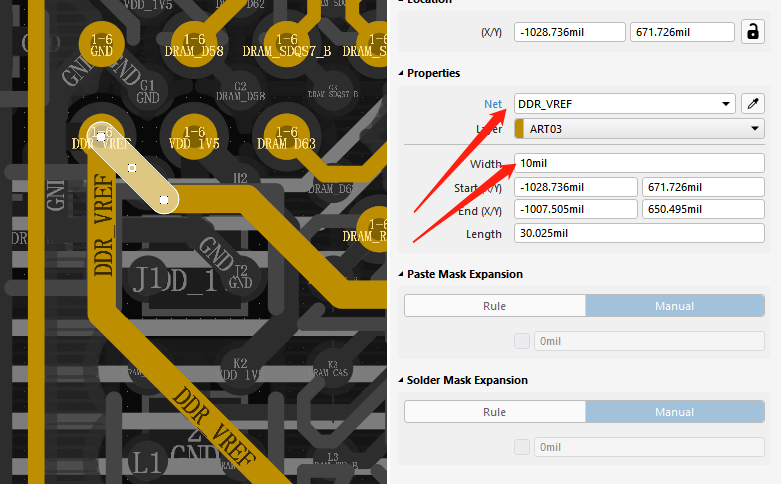
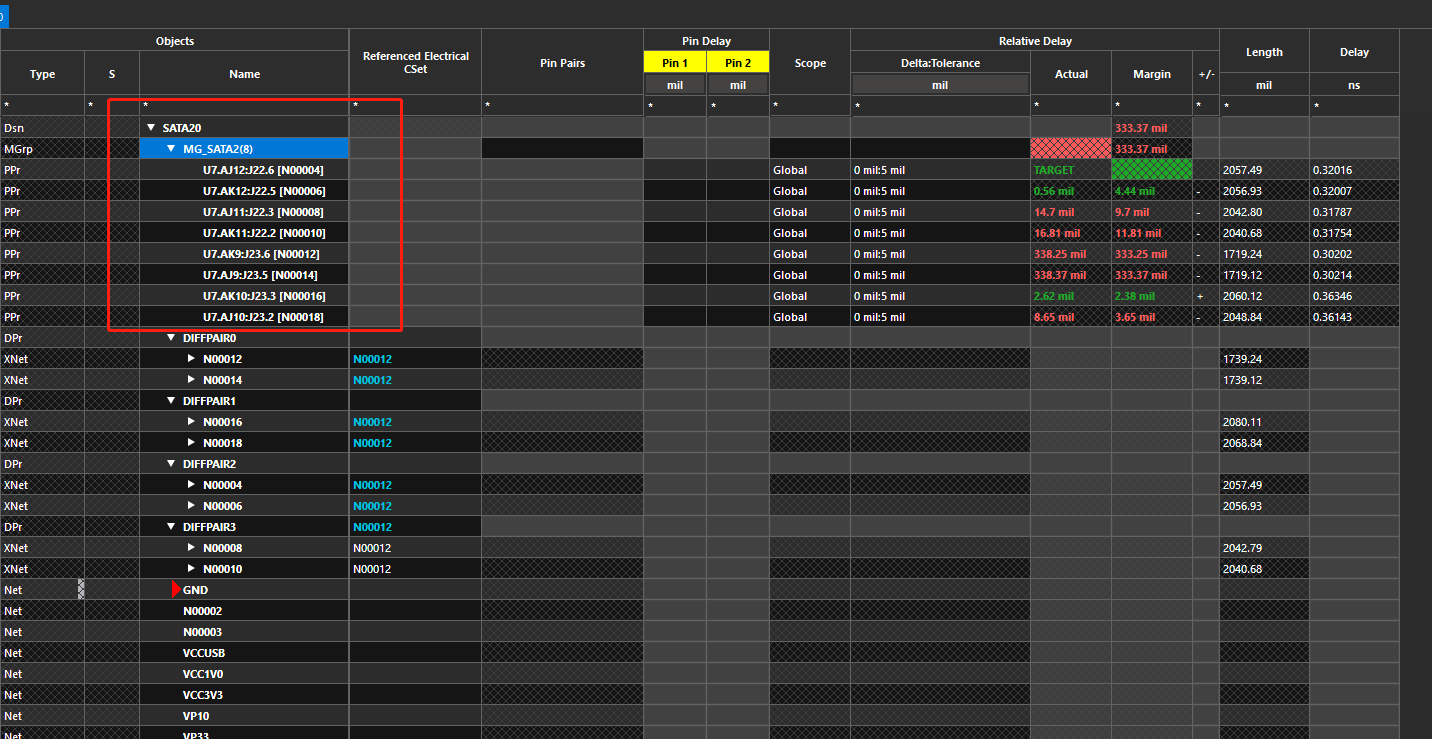
注意等长线之间需要满足3W规则2.VREF电源需要加粗到15mil以上3.等长超出误差值4.滤波电容尽量均匀摆放,确保一个管脚一个5.反馈需要加粗到10mil以上评审报告来源于凡亿教育90天高速PCB特训班作业评审如需了解PCB特训班课程可
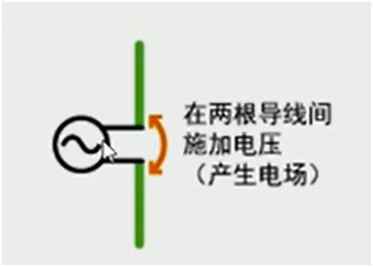
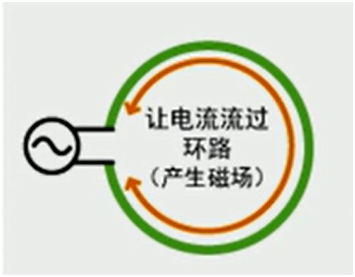
电磁兼容试验中的重要内容就是骚扰发射试验。因此,控制骚扰发射是一项重要的设计内容。为了控制骚扰发射,首先要找到骚扰源,然后采取措施消除它,或者截断它发射骚扰能量的路径。 EMI骚扰源有啥特征呢?以往广泛流传的是:高电压,大电流就是骚扰源。这种说法其实很片面。单纯的一个很高的电压,或者一个很大的电流,
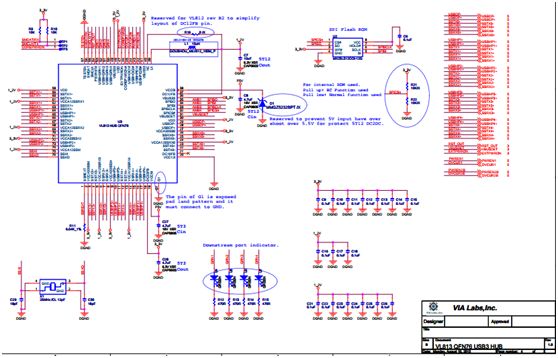
USB3.0 HUB方案之VL813USB3.0的HUB,看了目前市面上的产品,4端口的USB3.0的HUB也有不少用的是VL813方案。下面分享下该芯片方案,文末会贴出该方案的下载方法。 VL813封装为QFN76,原理图部分如下图。参考设计来
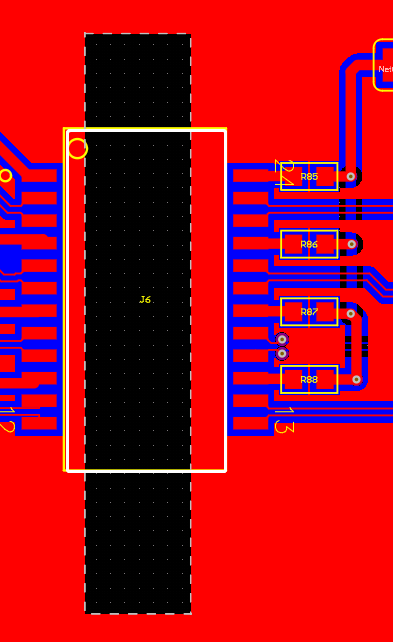
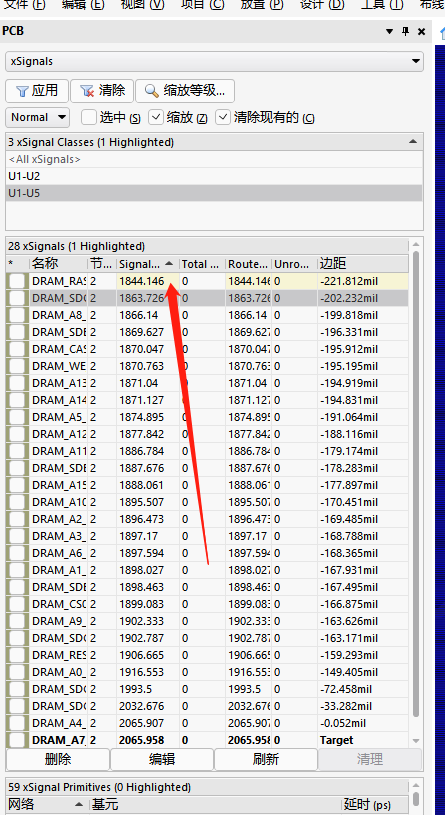
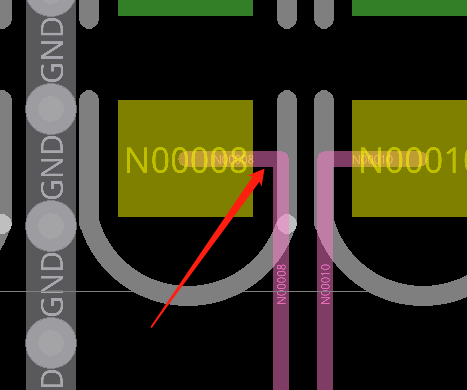
差分线对内等长误差5mil,同一组差分误差5mil规则要分开进行设置,后期自己处理一下2.焊盘出线不要走直角3.差分对内等长尽量在不耦合处进行等长4.注意器件摆放不要超出板框5.差分走线要耦合走,后期自己优化一下6.后期自己在地平面铺铜,把
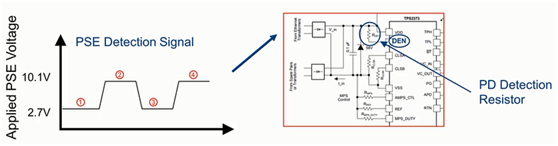
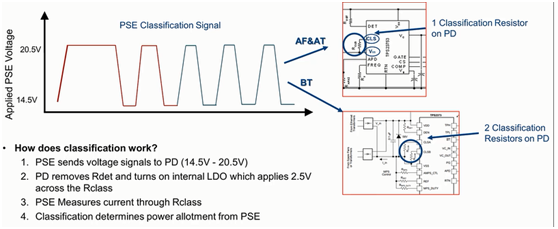
最近有看到一个TI的关于POE的培训,分享给大家,文末有下载方法。 什么是POE供电?POE供电也称为以太网供电,是一种在以太网中可以通过CAT5双绞线同时传输以太网信号和电力。POE的装置包含两个部分,一个是供电端,Power Sourcing Equipment,简称PSE,常见的产品有交换机,
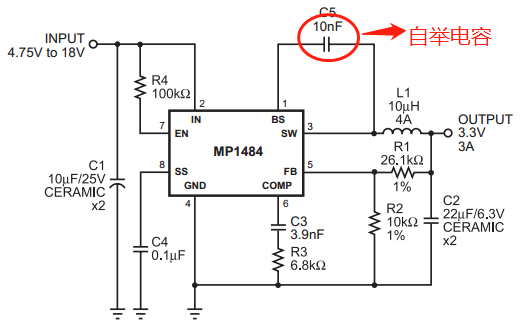
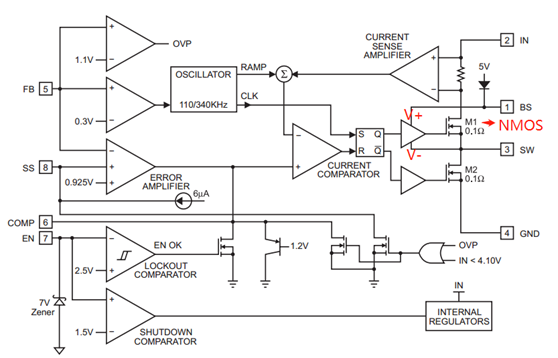
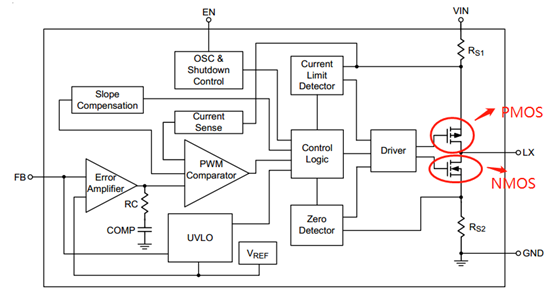
在BUCK电路中,经常会看到一个电容连接在芯片的SW和boot管脚之间,这个电容称之为自举电容,关于这个电容,有以下几个问题。 自举电容有什么用?以MPS的buck芯片MP1484为例。规格书中芯片的BS管脚说明如下:在BS和SW之间接一个0.
如果说,新能源汽车车主的最大痛点,那一定是充电基础设施不足,人人有充电难的问题,虽然新能源车企用诸多方法来解决,但依然有很多车主不敢买新能源汽车,但现在这个问题或许即将被解决。近日,华为成功举办“2024华为智能电动&智能充电网络战略与新品
人工智能(AI)是一项进步,使计算机和机器能够复制人类的知识和解决问题的能力。如今,人们正在使用人工智能识别门牌号码。人工智能可以单独或与其他技术相结合来执行任务,如传感器、地理定位、机器人技术,无需人类参与。人工智能在识别门牌号码方面的作
电阻式位置传感器是一种基于电阻变化的位置测量装置。它通常由一个可移动的触头和一个固定的电阻元件组成。当触头移动时,电阻值会随之变化,从而可以测量出物体的位置。电阻式位置传感器具有简单、经济、可靠等特点,被广泛应用于工业自动化、汽车、机械等领
在PCB制造过程中,很多厂商为了能够快速批量生产产品,同时也要照顾其质量稳定性,会选择配备工艺边工艺,那么你知道PCB工艺边有哪些常见的加工方法?1、V-cut这是一种通过在PCB板上进行切削加工出V形槽的方式。零间距的V-cut有利于保证
发文章
7天EMC特训营
LED灯维修案例
零基础电子设计中的《万用表》
射频电路第9节微带天线的设计
layout设计6层叠层阻抗计算速成实战视频课程
基于51单片机的洗衣机设计
2024-04-17 17:34
2024-03-21 16:06
2024-03-08 15:34
2024-02-28 11:03
2023-08-21 16:30:02
2023-08-26 13:52:07
2023-08-26 13:52:41
2023-08-26 13:52:59
2023-08-27 22:52:59
2023-08-30 15:55:42
2023-09-09 14:36:37
2023-09-09 15:31:00
2023-09-09 15:41:33
2023-09-09 16:37:29
2023-09-09 16:38:54
我要投稿
技术文章
视频教程
百问百答
下载APP
在线客服
 扫码关注
扫码关注